
Utilizing GPT 4 for Extracting Data from PDFs: An In-Depth Tutorial
In the current era, many aspects of our lives have become digitalized. The most common example of this is the conversion of paper documents into digital formats. This is happening in various offices or businesses around the world.
Because of such digitization, a file format known as PDF has become quite popular. If you are related to a professional setting, then you must know about this as a majority of official files are saved and shared in this format.
Despite being such a popular format, it has a few limitations. On top of these limitations is the fact that the content inside PDFs cannot be edited or altered. So, in this article, we will show you how this content can be extracted with the help of a recent technology named GPT 4.
What is GPT 4?

GPT 4 is an advanced model of the standard Chat GPT 3.5. This model of chat GPT has much higher understanding capabilities. Unlike the traditional chatbot, this model can also understand and generate images. It doesn’t solely rely on textual commands.
Since GPT 4 can access the information inside images, it can also be used to make the information present inside PDFs editable. In the following, we will go over this process thoroughly so that you understand how this technology can be used to harness PDFs.
How to Use GPT 4 for Extracting PDF Data?

This process comprises a few steps. Those are given in the form of headings in the following.
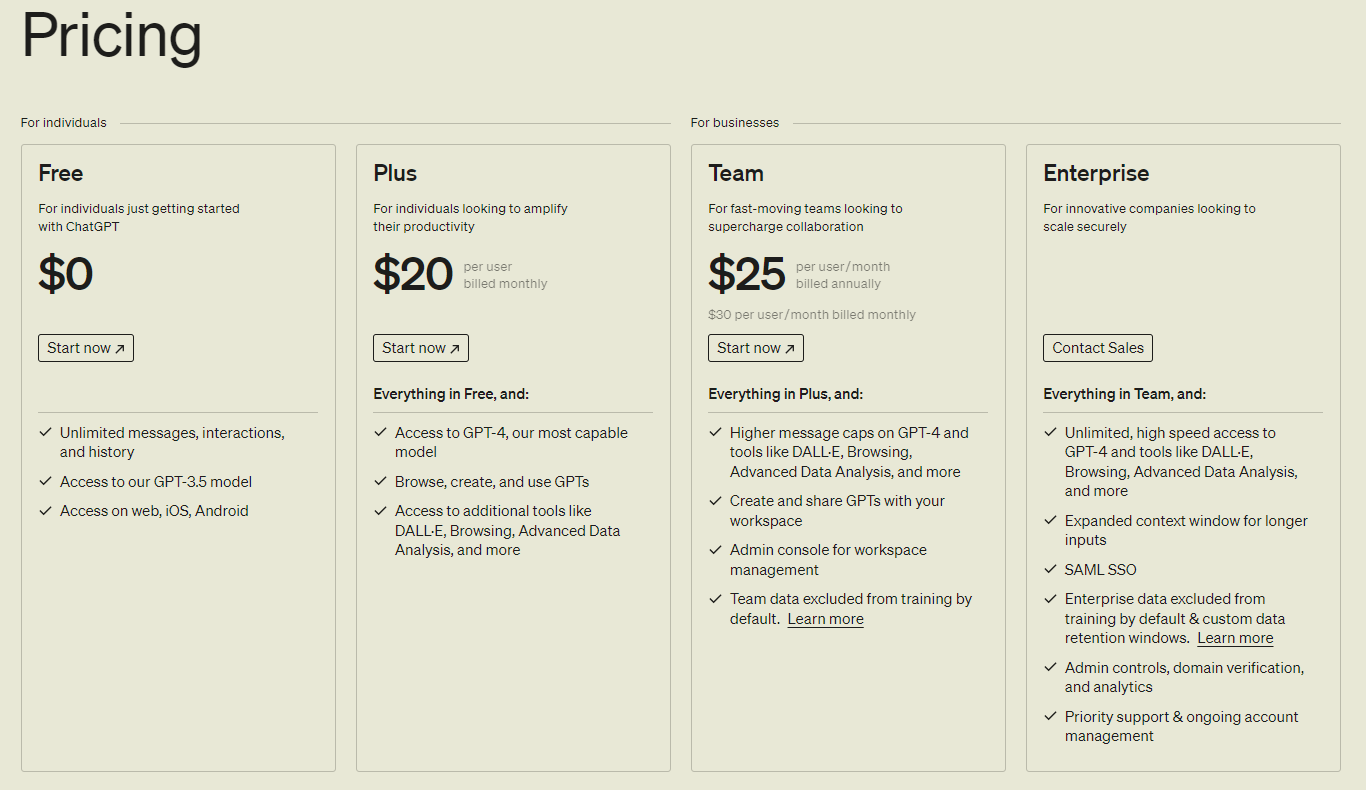
1. Subscribe to GPT 4
First, you need to purchase the GPT 4 subscription. In the free plan, you can only use GPT 3.5. That version can only converse in textual commands. This means it can’t be used for PDF extraction. So, as a first step, you will subscribe to the monthly subscription of GPT 4. If you want to learn about the details of this tool’s pricing, click here.
2. Upload the PDF Files
Next, you have to upload the PDF files that you want to extract.
Make sure they are the right files and insert them into the GPT 4 tool. You can do this by dragging and dropping the files from your computer.
3. Provide the Required Command
GPT 4 has the capability to understand the content inside PDFs contextually. That’s why you can enter any command along with your PDF file in this tool. The most standard command in this regard would be ‘Extract data from this PDF in the form of plain text.’ Similarly, you can also provide customized commands such as, ‘Extract text from this PDF and fix grammar mistakes from it.’
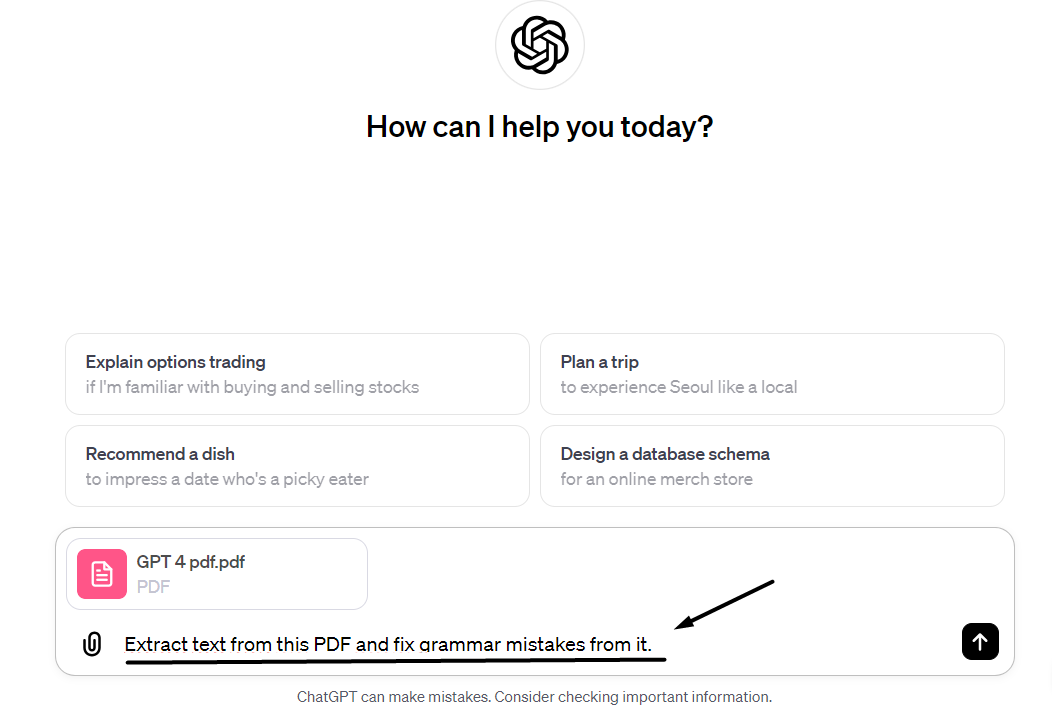
4. Enter the Command
Finally, you have to press enter. This will send the message to GPT 4, and it will start processing your command. While this processing is happening, the tool will also take into account the additional instructions that you provided.
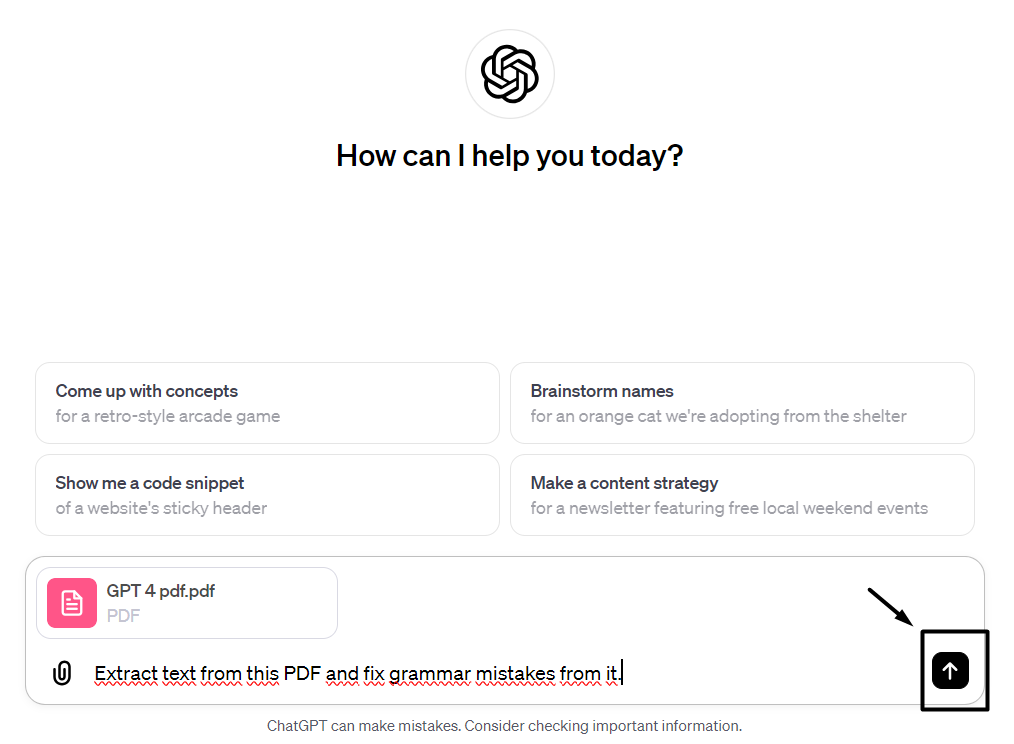
5. Collect the Results
In the end, the results will be presented to you in the form of textual content. You can copy or edit this text as you wish. In this way, the data in your PDFs get extracted with the help of GPT 4.

Importance of Extracting Data from PDFs
You might already be familiar with the advantages of retrieving data from PDFs. But we will still share some of them to make things clearer.
1. Editability

The most obvious purpose of converting PDFs into text is to edit the content inside it. As we mentioned in the beginning, PDFs are not directly editable. However, the data present inside them might get updated with time. So, instead of creating new files every time for some updates, we convert them into text and edit content easily.
2. Clear Readability

Sometimes, PDF files are of low quality. This means that the text inside them is barely readable. For people with sensitive vision, these types of files are extremely hard to read. In this case, extraction of text is helpful as plain text is mostly clearer.
3. Analysis of Data

This benefit can only be achieved with the help of AI tools. You can extract and analyze the data from PDFs by entering it into an analytical tool. For example, you can enter the content into a readability checker to see if the data inside the PDF is easily understandable.
Alternative Method

Extraction of text from PDFs using chatbots is useful only if you want customized extraction. However, if you are only interested in the conversion of PDFs into plain text, then you can use an alternative solution. The good thing about this method is that it is completely free in some cases.
Here are the steps that you have to go through to use this method:
- Go to an online PDF to Text converter.
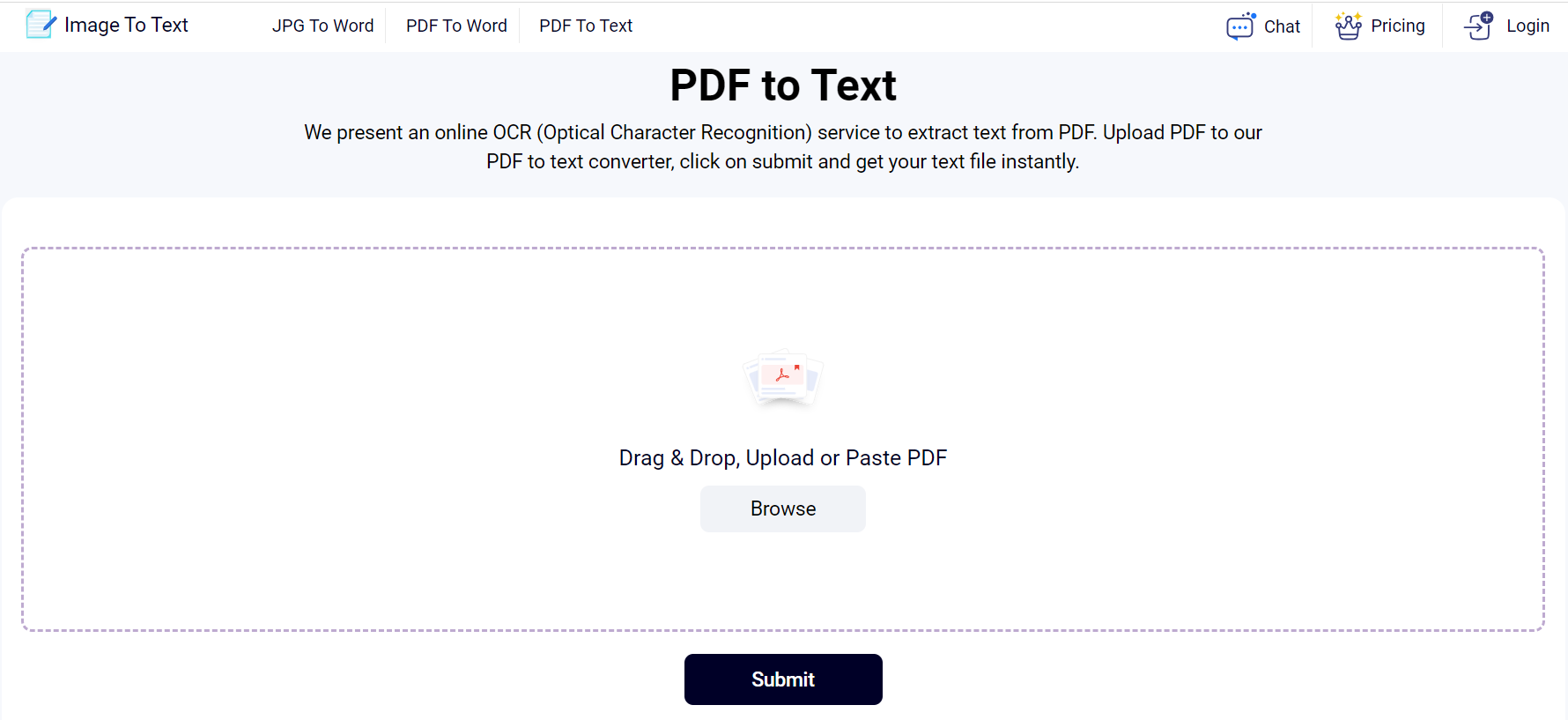
- Upload your PDF into the tool. There are several methods of uploading in these online tools. For example, drag and drop, browse files, etc.
- After that, click on the action button. These are usually labeled submit, convert, or start.
- Then, the process will take a few seconds. When the process ends, you are shown the plain text that you need.
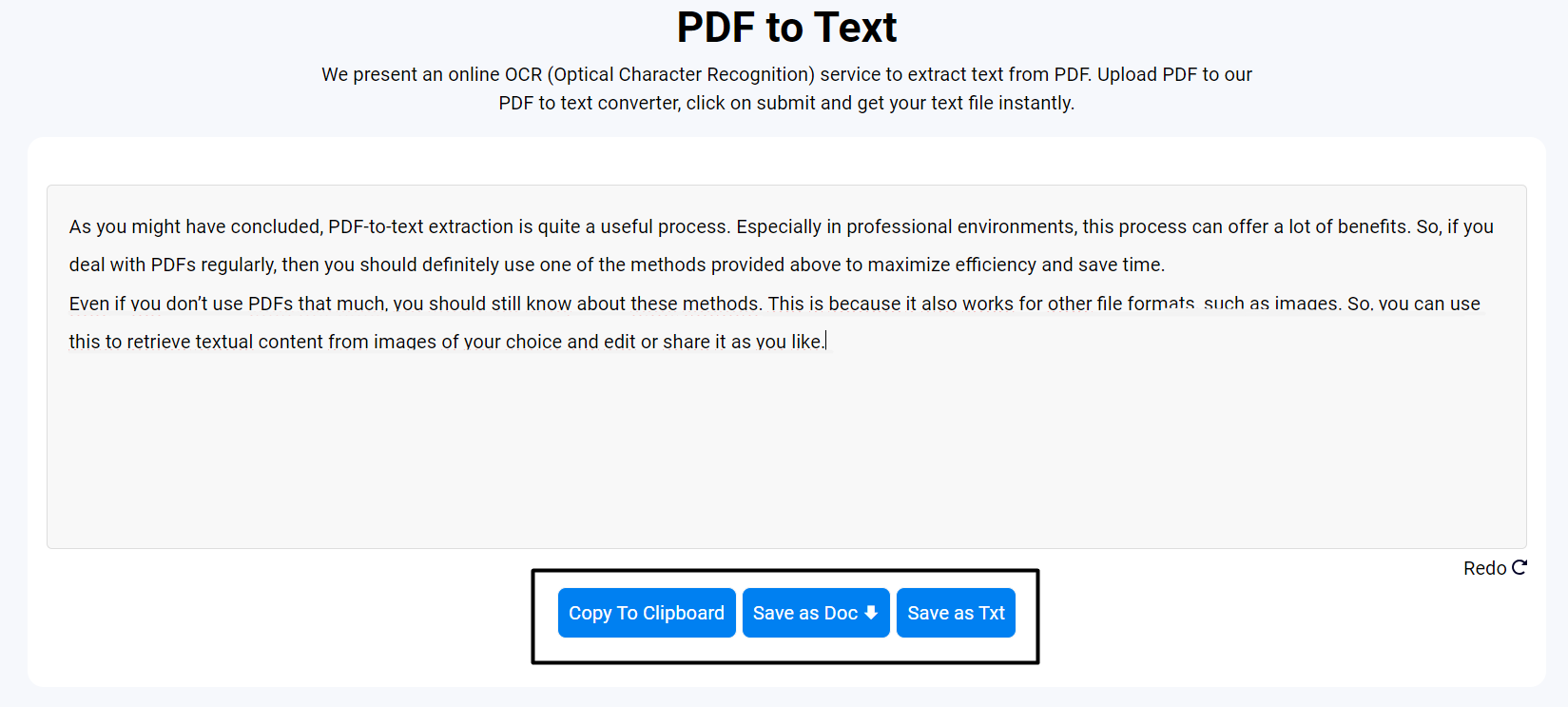
In this way, a simple process allows the conversion of PDFs into text. This method is much faster than its chatbot alternative. However, there is less customization in this. So, based on your needs, you can use either one of the methods.
Conclusion
As you might have concluded, PDF-to-text extraction is quite a useful process. Especially in professional environments, this process can offer a lot of benefits. So, if you deal with PDFs regularly, then you should definitely use one of the methods provided above to maximize efficiency and save time.
Even if you don’t use PDFs that much, you should still know about these methods. This is because it also works for other file formats, such as images. So, you can use this to retrieve textual content from images of your choice and edit or share it as you like.


